SQL Azure Data Sync
For quite a couple of years now, the SQL Data Sync software has been available to synchronize data between MS SQL Server databases. This SQL Data Sync however has been decommissioned and we have to resort to the the (new) SQL Data Sync (Preview) nowadays.
SQL Data Sync is a solution/feature which allows you to synchronize data between several SQL (Azure) databases. The best thing is, you don’t have to synchronize your complete database. You can choose which tables and columns need to be synchronized. This is a very nice feature if you have, for example, your database scaled out in multiple regions of the world and some of the data has to be kept in sync.
The new SQL Data Sync has been made available through the Azure management portal. When navigating to the SQL Databases tab you will have an option available to Add Sync, which will create a new SQL Data Sync group_._
For the purpose of this post I have created 2 databases, one located in West Europe and one located in East US.
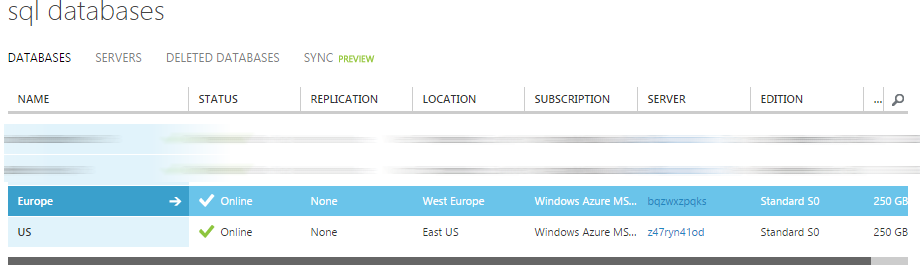
To keep them synchronized I’ve added a new Sync Group via the portal.
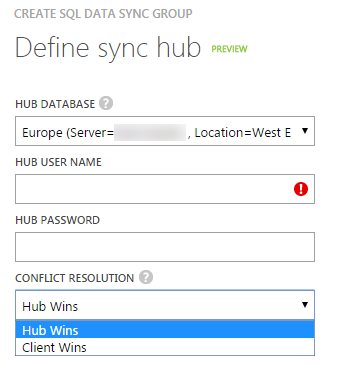
When creating the sync group, you have to specify which database will operate as the Hub. Basically this means which database will be the master. It’s also possible to select the conflict resolution in this step. The default value is Hub Wins, but you can also specify the client should win in case of a conflict.
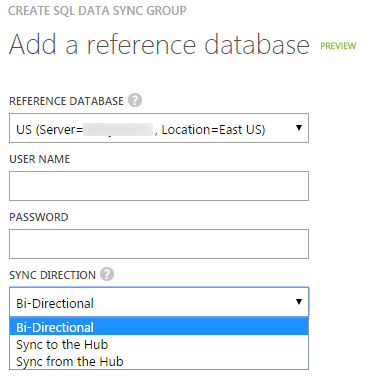
On the next step you will be able to add the first reference database. For me this will be the database located in East US. I’ve also selected the Bi-directional synchronization direction. This means updates in the client will also be pushed back to the Hub and updates in the Hub database will get pushed towards the client.
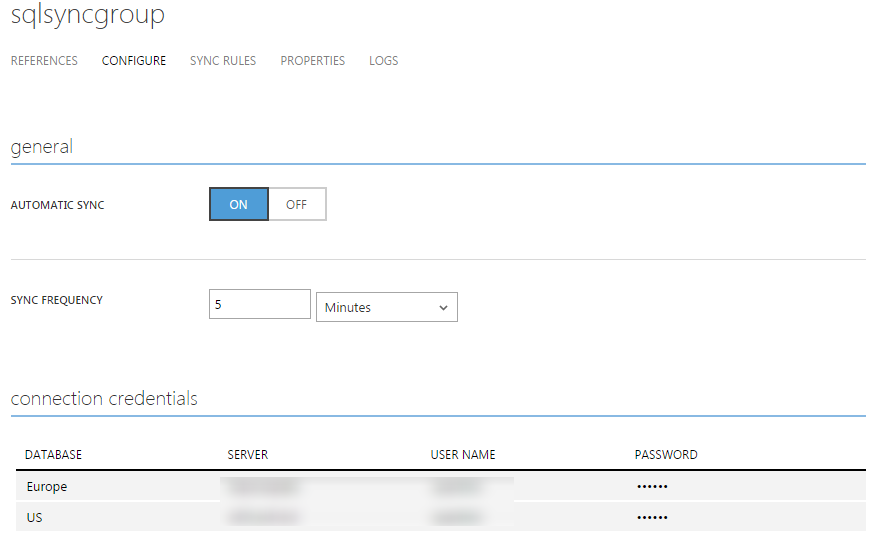
Once the sync group is created you can start configuring the synchronization options.
The second tab, Configure, is meant for global configuration, you can activate the synchronization, set the frequency and update the connection settings. Important, but not very exciting.
The third tab, Sync Rules, is a lot more exciting. Over here you can specify which tables and columns have to be synchronized between the databases. In order to see any data on this screen it is necessary your database has already a scheme defined. Therefore I’ve created several tables into my Europe database with this script:
CREATE TABLE TestTableForSync
(
Id INT IDENTITY(1,1) PRIMARY KEY,
Name NVARCHAR(30),
Description NVARCHAR(255)
)
CREATE TABLE TestTableNoSync
(
Id INT IDENTITY(1, 1) PRIMARY KEY,
NoSyncName NVARCHAR(30),
SomeValue NVARCHAR(40),
SomeMoreText NVARCHAR(255)
)
CREATE TABLE TestTableNoPrimaryKey
(
Id INT IDENTITY(1, 1),
NoSyncName NVARCHAR(30),
SomeValue NVARCHAR(40),
SomeMoreText NVARCHAR(255)
)
CREATE CLUSTERED INDEX TestTableNoPrimaryKey
ON TestTableNoPrimaryKey(Id)
You will probably notice, from reading the table names, I want 1 table to be synchronized between the databases. Another thing you will probably notice is me creating one table without a primary key. This third table, TestTableNoPrimaryKey, has a clustered index (necessary for adding records in SQL Azure), but no primary key. This table is added to show you something which is quite important to understand.
After refreshing the screen with the Sync Rules you will see something similar as the picture below.
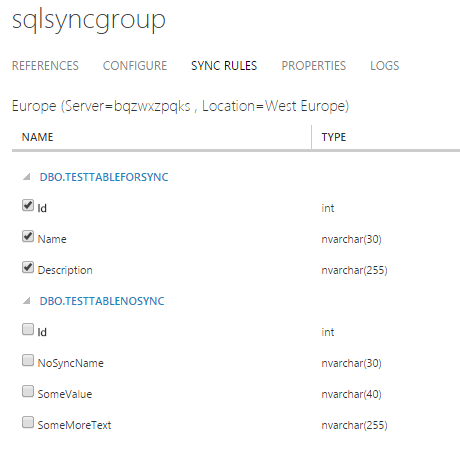
Notice there are only 2 tables in this list. The table without the primary key, TestTableNoPrimaryKey, isn’t listed on this screen. The reason for this is the Sync needs a primary key to handle the synchronization between the different databases.
Because I want all the columns of the table TestTableForSync to be synchronized, all columns are checked. Saving these changes will activate the synchronization and all changes will be executed immediately. After waiting a few moments you can run the following query on the client database (US) and see the results are the same compared to the Europe server.
SELECT *
FROM TestTableForSync
If you run a SELECT-query on the other tables, which aren’t synchronized, you will see there aren’t any changes made within these tables.
Awesome, isn’t it?