When working on a project that’s being distributed you are often required to create a NOTICE file giving the necessary attribution to work you rely on. As written on the Apache site on this topic:
If the Work includes a “NOTICE” text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License.
It’s not hard or complex to create these files, but it’s a LOT of work when starting.
Read more →It has been twenty years already!
Twenty years since I started my professional career. Of course, I had some side-gigs during college and a couple of internships, but I’m not counting those. After graduating in January 2005, my first real job started on February 1st, 2005, as a software engineer at Ordina, a large consultancy company in the Netherlands.
Over the years I’ve had the privilege to work with quite a few awesome persons, work on great projects and doing stuff I always dreamed of. I’ll reflect a bit in this post and say thanks to some of the people who have been the most influential in my career.
The start
My career started at Ordina as a software engineer. The team was responsible for creating (enterprise) applications on Pocket PC/PDA handhelds. Do you still remember those?
The operating system back then was Pocket PC 2002, Windows Mobile 2003, and Windows Mobile 5.0 later. The .NET Framework was still new during this time and on these mobile devices we had to resort using the Nano Framework or Compact Framework (if lucky). We weren’t that lucky, so had to use a very stripped-down version of C++. Most of the time we couldn’t use the ATL or MFC libraries due to hardware constraints.
I had not learned C++ during college, so that was a steep learning curve. My team consisted of some great colleagues who are experts in this field who were able to learn me a lot on how to build an application and user experiences on mobile devices. The latter has certainly helped me a lot later in my career, because mobile devices have become quite important this day and age.
Read more →It’s not something a lot of people need to do on a regular basis, but when you do, you don’t want to spend a lot of time doing it. I’m referring to the process of “create an SDK for your APIs”.
When your service is exposing endpoints for your consumers to use, it’s easy to refer them to using raw endpoints and let them figure out how to deal with it based on the Open API specifications (formerly known as Swagger) provided. This requires quite a bit of plumbing on their part.
Needless to say, invoking endpoints from your API by using HTTP-calls isn’t very user-friendly and quite error prone. Providing your consumers with a proper SDK is much better from an onboarding perspective.
How to start building an SDK?
As mentioned, either you or your customer needs to do quite a bit of plumbing to invoke your API endpoints properly. This isn’t something anyone will enjoy, so automation is everyones friend over here.
To start, you first need to make sure you are generating Open API specs for the API. Just about every ecosystem has generators for this process. In het .NET ecosystem we’ve been using Swashbuckle for a couple of years now, and with the release of .NET 9 there’s also out-of-the-box capabilities to generate the API specifications.
With these files generated, you’re already halfway of creating an SDK. For best results, be as complete as possible with your Open API specs. Provide descriptions, all error codes, use DTOs, adhere to the HTTP specifications, etc.
Read more →I like creating complex solutions for simple problems just as much as every other engineer. That’s why I have dozens of side-projects going on where I’m trying out stuff. During my day job, I try to provide as much value to the customer/business with the most simple, most performant and cheapest solution I can think of.
That’s where Copilot Studio comes into play.
You’ve probably read a ton of posts and articles about bring-your-own-data, RAG, finetuning LLMs, etc. for the past couple of years. All great stuff and are great solutions for adding Generative AI to your solutions. However, most of the time this requires a lot of engineering effort, time, and adds quite a bit of overhead.
Copilot Studio provides you capabilities to build your own agents, integrate them within your own environment and make the created Copilots available to your organization or the public, all with only a couple of clicks inside the portal. It’s a low-code experience compared to working with Azure AI Studio, or making your own solution with Azure Open AI. A low-code solution comes with a ton of benefits, but is also limited in capabilities compared to the ‘pro-code’ solutions. It’s a trade-off.
To get the hang of Copilot Studio I’ve started to create my very own Knowledge Base for this blog, so I can ask it questions and answers come up based on the posts I’ve had in the past. Similar to using search, but better!
Read more →I’ve been having issues with Disqus for a while now. Comments weren’t always placed under the correct post and I’ve done some extensive troubleshooting on it, invoking the Disqus API to resolve, added custom (meta) header fields on the pages. So far, I haven’t been able to fix it on all posts so have been looking for another system to facilitate adding comments to the posts.
This blog is a static website, created via Hugo, so no databases, only Markdown. I don’t want to add some repository to this to keep the performance high and costs low.
I became aware of two commenting systems using GitHub Issues or Discussions as their underlying platform, last week. There’s giscus and utterances. Both appear to do a similar job, one using GitHub Issues, the other GitHub Discussions. There’s no real preference for me from the technical point of view, so I randomly picked one of them and picked giscus as my new commenting system.
The homepage has all the information I needed to get this up and running.
One needs to create a public repository to host the discussions, add the giscus app to the repository and turn on GitHub Discussions. All fairly straightforward.
Once everything is set up by going top-down from the the giscus homepage you’ll end up with a script-tag that’ll load an iframe on your page.
Read more →The current large language models, like GPT-4, GPT-4 Turbo and GPT-4o are great when you need some output generated based on data you feed in the prompt. Even the small language models, like Phi-3, are doing a great job at this. However, these models often don’t know a lot about the data within your company. Because of this, they can’t do a good job at answering questions that required data from your organization.
There is of course the M365 Copilot available, which is able to index all of the organization its data and provide answers based on it. On a high level, what this is doing, is using Retrieval-Augmented Generation (RAG). There’s a decent post about this on the IBM Research site and there’s also a good post on the AWS site on it.
By using RAG in combination with your LLM, you are able to index your own data and let the model interpret it.
A great way to get started with this, is by using the Azure Open AI Assistants feature. The MS Learn page on this topic is quite good. If you’re interested in the topic, I’d suggest to check it out: https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/assistant.
Get your data
The first thing you need to do is make sure all data is available to the assistant. At this moment, there’s a large list of supported file types, like docx, pptx, pdf, png, txt, etc. The most important file types for us engineers are CSV, JSON, and XML, because these are able to hold (semi-)structured data so the LLM can infer relationships and create appropriate answers.
Read more →My disk was full the other day, so I needed to clean up. First the obvious stuff, like the Downloads-folder, the Nuget-cache, the bin- & obj-folders and the Temp-directory. Second, I used WinDirStat to figure out where the other biggest culprits of data-usage are to be found.
One of the directories was the main project I’m working on, with a staggering 24GB in disk size! Obviously, we’ve created a lot of code in the past years, but not THAT much.
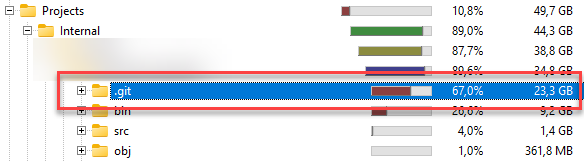
The cause of this, is at some point in time we committed a large file in the repository and it got a couple of revisions over time. Of course, we all know we should not commit large files in a Git repository and there are better solutions (Git LFS), but real-world happens.
What not to do
In short, don’t nuke the file from your repository.
This messes up a lot of stuff for the other contributors. While it might be the best solution, it will break other peoples workflow. But if you don’t mind this, or are the single contributor, feel free to play around with the suggestions shared over here: https://www.baeldung.com/ops/git-remove-file-commit-history
Read more →A friend asked me a question, a while ago, stating:
Hey Jan,
One stupid question around which I have thought a lot and often get stuck while deciding.
When to make a function static/non-static specifically the helpers or utility ones.
I read 2 arguments
- All the functions that don’t need to use a state of the object, (don’t update any variable value of the object ) should be static.
- All the functions that should/can be test independently and have some logic. Not only transformation or mapping. Should be non-static.
These 2 arguments are against each other and are often confusing, and mostly in the context of our repo. We often use multiple resources and their clients to implement a logic.
Now these mostly don’t update any state of an object, mostly the value of the attributes of the class are read, never updated. And it does make sense to test them independently
One example
Reading from the storage account, filter data based on some logic and then updating that in, let’s say, a Function App.
Now, how do you decide?
Let me start by: There’s no such thing as a stupid question in engineering! These are the type of questions everyone is wondering about, but only few dare to ask. Iris Classon has done an entire blog-series on these ‘not so stupid questions’.
Read more →A few years ago, I was assigned on a project with a friend of mine, Marnix van Valen and we needed to update our APIs in API Management with the latest Open API schema for each release. As we don’t like to do this work manually, it got added to our build- and release pipeline. I like this approach, as it removes the need to host Swagger / Open API compute on my own service and only static files need to be hosted in some folder.
So I started re-implementing the approach we did a couple of years ago.
Turns out, this still works! Well, it would if the packages were still kept up-to-date with the latest ASP.NET features.
No minimal API support
Like many engineering teams, we adopted to use the (recommended) minimal APIs to create the services. Apparently, this doesn’t play nice with the Swashbuckle tooling. There are multiple issues at GitHub on this topic. All without a resolution, aside to migrating back to the ‘old’ way of working with a Program.cs and Startup.cs class.
I understand the core maintainers have different priorities nowadays, but this estimated 15-minute task now took up more time from my part.
Only running on .NET 7
There’s another problem I encountered. The Swagger CLI 6.5.0 tooling only has support up to .NET 7. Our build agents don’t have this version installed anymore.
Lucky for me, there’s an environment variable you can set to make sure the latest version of .NET is being used.
Read more →Aside from Azure Traffic Manager, Azure Functions, and Azure Service Bus, Azure API Management (APIM) is one of my favourite services to use in just about any solution.
A useful little nugget for APIM is it’s able to have its own Managed Identity. You can choose to use a System Managed Identity or a User Managed Identity. Both options have pros and cons.
When you have configured APIM with a managed identity, this identity can be used to authenticate with the backend services.
This can be useful in a wide variety of scenarios, but do be careful configuring this. By using this feature, every request to the backend will use the token of the Managed Identity and not of your users or services making authenticated requests to APIM.
As mentioned in the docs, to set this up, you can use the authentication-managed-identity policy for inbound requests.
When doing so, you need to specify which backend resource to use (App URI ID of an App Registration), and the name of the variable to put the token into.
<policies>
<inbound>
<base />
<authentication-managed-identity resource="api://07601ff2-0b86-40f2-b5d9-7f8db33c9fb7/" output-token-variable-name="msi-access-token" ignore-error="false" />
<set-header name="Authorization" exists-action="override">
<value>@("Bearer " + (string)context.Variables["msi-access-token"])</value>
</set-header>
</inbound>
<backend>
<base />
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
Very useful in many scenarios, but do be careful of the downsides of using the APIM managed identity to be the authenticated party for backend services.
Read more →