Designing a microservices architecture
There are dozens of blog posts, articles and books talking about microservices. Some of them talk about the design, other on how to implement and even others talk about why and when to use them.
This post will be a combination of them all. I won’t claim to be the all-time-expert on the matter, but I have read quite a bit on the subject, attended some talks and have had the honor to design (and implement) such a solution a couple of years ago.
First and foremost, it’s important to understand a microservices design is just another standard architectural design pattern. This pattern can help you to create a high-performance, scalable software solution, but it can also bankrupt your company!
The short explanation
If you don’t have much time to read, or don’t really want to, here’s the elevator pitch for microservices:
It’s a set of small (independent) services, each of them able to carry out their own (functional/business) responsibility without having direct dependencies to other services.
The long explanation
Of course, such a short explanation is a bit short, to say the least.
The general overview
The microservices pattern is a combination of several other, well-known, patterns which we probably have been using for a couple of years now. Take for example the Service-oriented Architecture, Event-driven architecture, Database per Service, API Gateway / Backend for Frontend and many more. All of them combined can form an architecture which has multiple small services, all operating individually.
There’s an awesome picture on microservices.io (copied over here for completeness) drawing lines to dozens of patterns which are related to a microservices architecture.
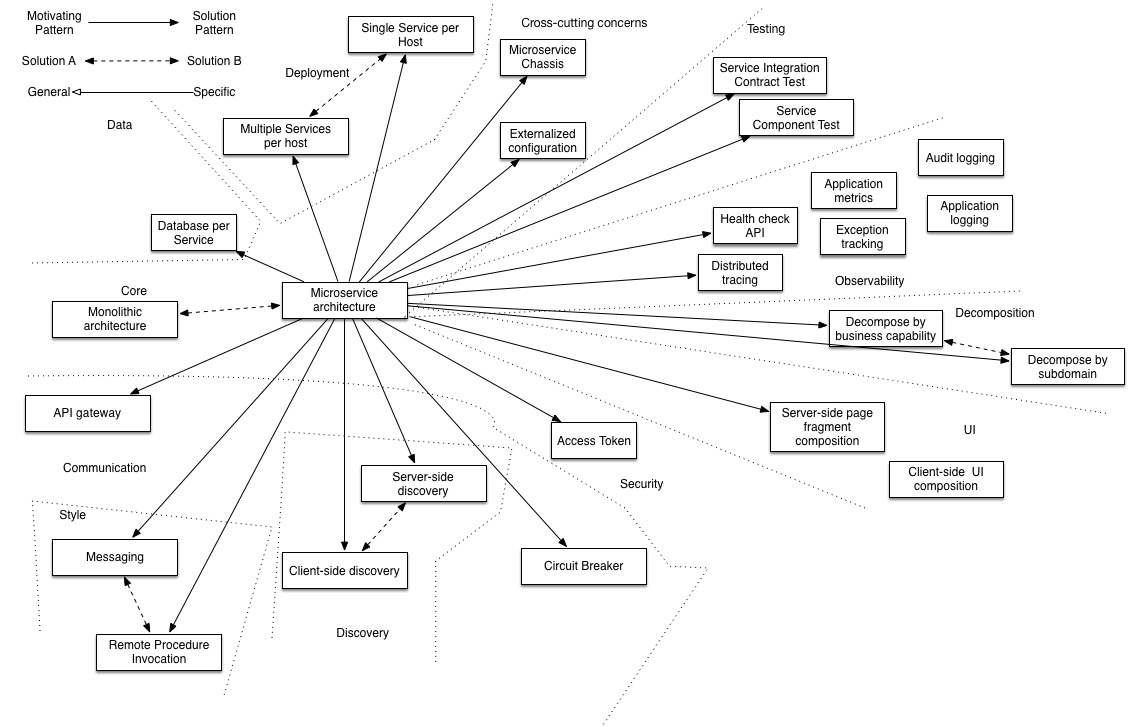
It’s recommended to have some experience with a couple of these patterns, before trying to implement the full microservices architecture. Even if you and your team have lots of experience, developing and maintaining this kind of a solution design can still proof to be complicated over time. Managing all these small services and keeping an overview requires quite some (software) management skills.
So, why would I want all this complexity?
An excellent question!
Keeping track of all those small, independent which might, or might not have some loosely coupled dependency to each different services can become quite a burden. Why would you ever want to encumber yourself with such a design?
Well, let’s take a step back and look at how we (I’m guessing about 98% of the software industry) have been developing software solutions in the past couple of decades. Most of the solutions are very big software systems with multiple layers, tiers, thousands of classes (I’m coming from an OO-background over here), specific boundaries, tightly coupled services, etc.
Many of us have been developing and maintaining these kind of solutions and we all know it can be very hard to learn these systems for new team members, but also to add, change or migrate functionality.
This is called a monolithic architecture. A nice diagram is shown below.

All of the business logic, data access, I/O operations and other stuff is bundled into one big system. Most of the time the Presentation/View layer is also put inside this big block.
I’m not saying designing and developing a monolithic software solution architecture is a bad thing. Each architectural pattern has its own use. Nowadays, most developers understand this type of architecture style as it has been quite a common way to design your software in the past couple of years/decades.
The major downside of this monolithic software architecture is changing different parts of the system. As said, most of the time all of the components are tightly dependent to each other and it becomes harder and harder to change functionality.
Let us not forget the deployment and testing strategies of these massive software solutions. I’ve been at a couple of companies where they got the deployment and testing in such a state they can deploy their monolithic software multiple times per day without breaking a sweat. However, most of the companies I’ve consulted at aren’t near this level of professionalism and deploying a new version also stresses out the teams.
If you are experiencing the issues mentioned above, or want to steer your software development in a more ‘agile’ way, changing your solution design to a microservice architecture might be a way to solve this. The idea behind this architecture is you can create dozens of small services which focus on one specific thing. This means these services will probably be easy to understand for the development team(s), but also to test the services and deploy them to the different environments.
Keep in mind though, migrating from a monolith architecture to a microservices architecture isn’t without risk and requires a lot of discipline and experience of your development & operations team. Most of the time I’d advice against such a migration!
When it’s easy to develop, test and deploy your solution, it should also be easier to change certain areas of it. This is the biggest win for a microservices architecture, in my opinion.
Some people say another big win is ‘you can write each service in the language/framework of your choice’. While this is true, I don’t think this should be the goal of your organization. If you are developing each service in a different programming language or framework, you loose one of the biggest advantages: learning to develop and maintaining the service.
Imagine you have 10 different services written in .NET Framework 4.6, .Net Core 1.0, .Net Core 2.0, Java, Ruby, Python, node.js, PHP and PowerShell. This means all of the developers need to learn these languages and different software designs of the services. The maintainability of such a solution will be worse compared to a large monolithic software solution written in a single language/framework. This is one of the reasons I’m a big believer in sticking to 1 or 2 languages per software solution. There might be a better fit in the solution for a specific problem, but if the overall solution will become even more complicated to understand I’ll pass and prefer to use the technique we are already using in other areas of the system.
So to conclude on the ‘why do you want all this complexity?’-question, it’s because this type of software design can make your software easier to develop, extend, test and deploy. All of these factors can cause a faster release-lifecycle, which means more business revenue. More business revenue means more profit!
So how do I get there?
Are you convinced creating a microservices solution might be a good idea for your next/current software solution?
If so, there are a couple of things to consider.
First and foremost it’s important your development team has basic understanding of about 60% of the patterns mentioned in the earlier diagram. Preferably more!
Now there’s another thing to consider, your software & network infrastructure.
While it’s completely possible to develop and deploy a microservices solution on-premise, I’d advise for you to go to a major cloud provider, like Microsoft Azure, Amazon AWS or the Google Cloud Platform. I’m a Microsoft fanboy, so I’ll advice Microsoft Azure of course!
The main reason to choose for a major cloud provider is the 24/7 support and they offer quite a lot of services which can help you create a proper microservices solution.
As I mentioned, it’s possible to deploy all of these services on-premise, but this will add additional load to your system administrators as they will have to learn and maintain all of the services and techniques you want to use in your software. This will also add some additional complexity to your deployment strategy and maintaining the software will probably be harder also.
Now that you are ready to create your microservices solution in the cloud you can start designing your first service. This first service will work like a charm and you will probably be able to deploy it within a couple of hours/days, maybe 2 weeks if you are unlucky! The development of the second service will probably go quite well also. Both of those services can operate individually without having any dependencies between them.
As the project moves along you’ll notice it will be useful if the services could share information with each other. This thought is where a lot of microservice solution architectures go to die. The moment one of the team members thinks it’s a good idea to call a different service from the service they are working in you are in trouble. Think about it for a moment.
If you choose to let the services work directly with each other, wouldn’t this be the same as a distributed monolithic architecture? In short: a monolith with latency?
Yes, it is!
That’s why it’s so important to understand the rules (or: guidelines) of a microservices architecture. I’ll repeat them again as they are so important and fundamental to the cause: Each service is able to carry out their own (functional/business) responsibility without having direct dependencies to other services.
So what does this mean?
This means each (micro)service is able to carry out whatever they need to do, without having the need for any (external) service. With ‘service’ I mean some other API or software service which lives in a different context.
This doesn’t mean you can’t use a database, cache, queue, etc. in your service. These are all systems which are necessary in modern development environments and help you create a stable, robust, scalable and performant service.
How would you design such a solution?
A couple of years ago, I was lucky enough to be hired as a solution architect on a project which was a perfect candidate for a microservices architecture. I won’t go into details over here, because it’s a confidential project.
At that time the hype of this architecture style was at its highest and there weren’t a lot of best-practices publicly available yet. However, because the project was such a perfect fit, I decided to go this route.
To this time I’m still quite happy with the overall design, even though there are some details I would have done differently in hindsight, which I can’t share a lot of info on.
Creating one or two services which can operate individually isn’t much of a problem. In this case it makes sense each service has some kind of service layer (REST API), business layer and probably even a data layer, your typical 3-layer software architecture.
Because you want to access data quickly a caching mechanism might be introduced (Redis Cache) and you need a ’normal’ database of course. Your first option might be a SQL Server database, which we all know and love. However, when you think about it, why would you choose a relational database type, like SQL Server, if all you are interested in is retrieving and storing data for your own little service?
It might be a better idea to store the data in some kind of NoSQL database (DocumentDBCosmosDB. This way you can do a single get- or insert-statement whenever you are working with data. No more need for denormalizing & normalizing data, joins, strange foreign keys, etc. By moving to a NoSQL database you can improve performance quite a bit.
Note: I still love SQL Server, but it might not be the most logical database to store data for your microservice. Think about it and decide for yourself!
What I’ve described so far isn’t very special and probably how you have been designing your software already. With the exception to the database, because its highly likely you have 1 (maybe 2) database in your solution design which is shared between all application logic.
The next part might be a bit new to you or your team, using some kind of service bus to communicate between services.
I already mentioned each service should be able to work independently of other services. But it might still be useful to share data between these services. We don’t want any direct dependencies between these services so this communication will be abstracted via the service bus. If something happens in a service, this service will send a message to the service bus. If there happens to be a service which is interested in this message, it can pick it up and work with this information.
Example
Imagine you have an ProductManagement-service and an Billing-service. If a product manager changes the name of a product from DocumentDB to CosmosDB in the ProductManagement-service, you also want to reflect this name change in the Billing-service in order to create proper bills. This means the ProductManagement-service will send a Update-message to the service bus. The Billing-service is able to pick up the message and will update its own data store with the necessary changes.
One thing you have to make sure is messages should be able to be picked up by multiple subscribers (logging service, audit service, other business services, etc.). The service bus should be able to implement some kind of pub/sub mechanism, for example the Azure Service Bus Topics.
A simplified diagram of the system I was designing a couple of years ago looks very similar to the following picture.
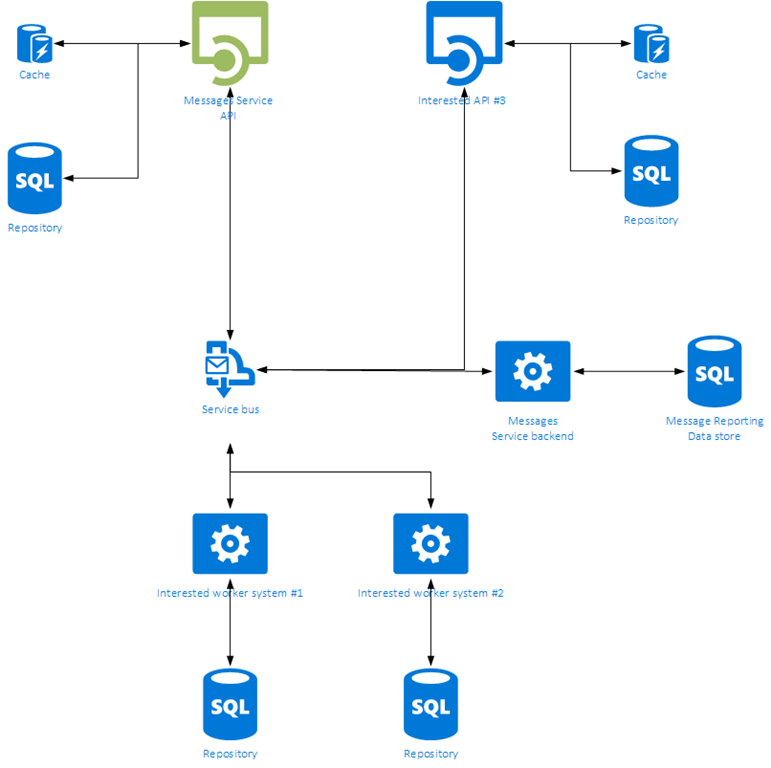
Over here I’ve highlighted the Messages Service API green to make it stand out. This service handles all things related to messaging (sending, retrieving, marking as read, archiving, etc.).
Whenever an action is triggered within this service, it updates both its own persistent storage (the repository) and its cache. When both of these repositories are updated, a message will be sent down to the service bus. This message will contain some details on the action executed, which might be useful to other services. Not all information sent will be useful to all interested services, but its not the responsibility of the Messages Service to keep track of this. The Messages Service only takes care of itself and passes along some information of the executed action in case some other service is interested in it.
In the diagram above you can see a Messages Service backend, which keeps track of all mutations of Messages and stores them in some kind of reporting repository. There are also a couple of other worker services and an API service, which are interested in Message mutations. Each of these services can subscribe to specific or all Message actions posted on the service bus.
None of the services are dependent to each other, but this way they still can share data. If Interested worker system #1 will send some kind of message to the service bus later on, any other service can act upon this message also.
Most service bus systems will allow you to filter on certain properties of messages sent which means your service will only act on messages it’s interested in.
Also note, the Messages Service API will also subscribe itself to any Message mutations posted on the service bus. This means it can update its own repository and cache if necessary when messages are retrieved from the service bus also. This might be useful if any other service needs to post something which the Message Service API will have to return to connected clients.
You will understand why this might be necessary when implementing a Backend for Frontend system. I’d try to avoid this in the beginning, but when your solution grows and you want more specific API’s for different clients, this will become more important.
Wow, while typing I noticed how confusing this Message scenario might be, because I’m writing about Messages (with a capital M) as actual object types and messages (lowercase) as any type of object posted as a ‘message’ on the service bus. Excuse me if this strikes as confusing to you.
What about latency?
This is one of the most common heard complaints when designing or speaking about a microservices architecture. Because there are so many services, each doing their own thing, people will think there will be a lot of latency and retrieving data will be quite slow.
If this is the case in your solution, you’ve probably made a few mistakes in the overall design. When following the design from the example above, you’ll see each service will have a direct connection to a repository (and probably even a cache) nearby. This repository is designed for specific use for this service, which means it should be blazing fast when querying or updating the data store. Overall, I think this design should be faster compared to your traditional (monolith?) design, because data is near the service tier so it doesn’t has to ’travel’ very far.
Remember, your service should be able to run independently of other services. So, effectively, there will be 0 latency in your system.
If your service is dependent on information from other services, it will retrieve this information via the service bus. Retrieving information via the service bus (or any other messaging system) will cause a lot of latency (most of the time a couple of milliseconds). We can’t do much about this, aside from keeping this in mind when designing the system. None of the services will have (real) realtime access to updated data from a different service, but all of the services will be eventual consistent. It’s up to you to determine if the latency of multiple milliseconds (maybe even seconds in the worst-case scenario) is something your services can afford for updating their repository data.
Managing the messages and system health
This is the hard part when designing, developing and maintaining a microservices architecture.
When having hundreds of small services, each doing their own little thing, it’s important to have some proper management tooling in place. Most major cloud providers offer such services, like the Azure Monitor and Azure Application Insights.
In order to properly use these services you have to implement the some logging mechanism in your services. Logging is very important when developing this kind of a solution architecture. No one will want to check each service individually to in order to find out if they have any errors.
With the logging in place you will be able to create awesome dashboards telling you if something is wrong or not. Even the latency and load of your services can be measured. Still, this requires some practice and you shouldn’t think too lightly on this matter. Keeping a good overview of your overall system performance and health is very, very important!
These operational insights is not something you should start considering near the end of the project. Creating logs and other insightful information should be implemented right from the beginning if you want useful and meaningful information.
To conclude
Implementing a microservices solution can be quite a pain in the beginning, but once you get the hang of it you will notice it will become easier. I’m a big fan of this kind of software design, if implemented properly!
There are dozens of other factors you have to consider which I haven’t mentioned in this post. If you like, I can dedicate some other posts on these matters, just drop me a comment and I’ll see what I can write up.