Smaller repositories on disk with Git sparse checkout
My disk was full the other day, so I needed to clean up. First the obvious stuff, like the Downloads-folder, the Nuget-cache, the bin- & obj-folders and the Temp-directory. Second, I used WinDirStat to figure out where the other biggest culprits of data-usage are to be found.
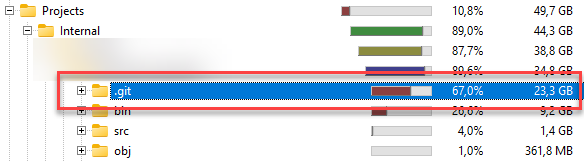
One of the directories was the main project I’m working on, with a staggering 24GB in disk size! Obviously, we’ve created a lot of code in the past years, but not THAT much.
The cause of this, is at some point in time we committed a large file in the repository and it got a couple of revisions over time. Of course, we all know we should not commit large files in a Git repository and there are better solutions (Git LFS), but real-world happens.
What not to do
In short, don’t nuke the file from your repository.
This messes up a lot of stuff for the other contributors. While it might be the best solution, it will break other peoples workflow. But if you don’t mind this, or are the single contributor, feel free to play around with the suggestions shared over here: https://www.baeldung.com/ops/git-remove-file-commit-history
I was also looking in doing something with blobless clones, partial clones, and treeless clones to see if filters can be applied via those means. Howevever, couldn’t fine a nice filter attribute to help with this.
What I ended up with
Asking the community: https://mastodon.cloud/@Jandev/112536194859017028
Via this way I got pointed to Git’s feature called sparse-checkout. I did see it before when browsing for a solution, but didn’t think it would fit my need.
After it got pointed out again, I did some more searching on it and found a very nice an blogpost on GitHub. This looks like a very nice feature for a mono-repo solution and you’re working on specific areas of it, as mentioned in the linked blogpost.
But also for me, for filtering a specific folder that’s storing the large file(s).
Step by step
Let me guide you through the steps I took to clean up my environment and save more as 20GB in my .git folder.
First delete the entire folder from the local system. Do make sure you store your stashes somewhere, and all your local branches are pushed to a remote.
Now do a new clone, but with the
no-checkoutflag:git clone --no-checkout <my-repository-location>.Navigate to the newly created folder.
Initialize the sparse checkout feature with the cone flag:
git sparse-checkout init --cone.Navigate to the
.git\infofolder and open thesparse-checkoutfile that should be there now. Update the contents of this folder to reflect something like this:/* !src/sub/folder/with/large/filesPull from the remote,
git pull origin.Work as normal!
Of course, if you’re interested in these large files, you need to add this folder to your local repository again.
For me, it saved about 20GB of disk size by filtering files that I’m not interested in anyway.

I do advice to read up on the offical docs and the linked GitHub blogpost, because the functionality is explained quite well over there.