Create an AI Assistant with your own data
The current large language models, like GPT-4, GPT-4 Turbo and GPT-4o are great when you need some output generated based on data you feed in the prompt. Even the small language models, like Phi-3, are doing a great job at this. However, these models often don’t know a lot about the data within your company. Because of this, they can’t do a good job at answering questions that required data from your organization.
There is of course the M365 Copilot available, which is able to index all of the organization its data and provide answers based on it. On a high level, what this is doing, is using Retrieval-Augmented Generation (RAG). There’s a decent post about this on the IBM Research site and there’s also a good post on the AWS site on it.
By using RAG in combination with your LLM, you are able to index your own data and let the model interpret it.
A great way to get started with this, is by using the Azure Open AI Assistants feature. The MS Learn page on this topic is quite good. If you’re interested in the topic, I’d suggest to check it out: https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/assistant.
Get your data
The first thing you need to do is make sure all data is available to the assistant. At this moment, there’s a large list of supported file types, like docx, pptx, pdf, png, txt, etc. The most important file types for us engineers are CSV, JSON, and XML, because these are able to hold (semi-)structured data so the LLM can infer relationships and create appropriate answers.
Because we can upload datasets to an Assistant, to answer a question we only need to get somewhat related data for a question. Take this question for example:
Get me the sales results from the last month, please.
To get a correct answer for this request, we need the following information:
- The current date
- The sales results
One might argue we need more information, or take assumptions, but for the sake of this post let’s assume a relative simple setup.
Retrieve a dataset
What the current LLMs are quite capable of, is creating SQL queries based on a schema. So for our use-case, it can be a good idea to do some prompt engineering to construct a query that’s capable of retrieving a dataset that has all the information necessary.
The first thing we need in the prompt is to specify what the current date is, so the model can determine what the previous month is. Or just use the DATEADD method with -1 month added.
The second thing we need is to identify all the necessary tables for sales results. As mentioned earlier I’m assuming a simple schema over here, so these are the queries that an LLM can come up with:
-- Query to retrieve sales data with customer and product details
SELECT s.*, c.CustomerName, p.ProductName
FROM Sales s
JOIN Customers c ON s.CustomerID = c.CustomerID
JOIN Products p ON s.ProductID = p.ProductID
WHERE s.OrderDate >= DATEADD(month, -1, GETDATE())
AND s.OrderDate < GETDATE();
-- Query to include sales staff information
SELECT s.*, c.CustomerName, p.ProductName, st.SalesStaffName
FROM Sales s
JOIN Customers c ON s.CustomerID = c.CustomerID
JOIN Products p ON s.ProductID = p.ProductID
JOIN SalesStaff st ON s.SalesStaffID = st.SalesStaffID
WHERE s.OrderDate >= DATEADD(month, -1, GETDATE())
AND s.OrderDate < GETDATE();
-- Query to include time-based analysis
SELECT s.*, c.CustomerName, p.ProductName, st.SalesStaffName, t.*
FROM Sales s
JOIN Customers c ON s.CustomerID = c.CustomerID
JOIN Products p ON s.ProductID = p.ProductID
JOIN SalesStaff st ON s.SalesStaffID = st.SalesStaffID
JOIN Time t ON s.TimeID = t.TimeID
WHERE s.OrderDate >= DATEADD(month, -1, GETDATE())
AND s.OrderDate < GETDATE();
Disclaimer: I have used Microsoft Copilot to come up with these queries, without specifying a schema, so this is purely to illustrate the point.
Construction of the proper queries might take some time, but in general the GPT-models I’ve been using are quite good at coming up with valid T-SQL queries when a schema is specified. Also take into account, we don’t need perfect queries, only datasets containing information we might want to use.
Use the data
When you’re finished creating the queries and invoking them, it’s time to store the datasets in either JSON or CSV files. I’m using Python over here because I’m using it on a regular basis nowadays.
for i, query in enumerate(sql_queries):
print(f"Query {i}:\n{query}\n")
response = await execute_sql(query)
with open(f'{context_folder_path}query_results_{i}.json', 'w') as f:
json.dump(response["SQL_Result"], f, cls=DateTimeEncoder)
Create a vector store
There are two ways you can chat with your data using an Assistant:
- In-thread files
- Out-of-thread vector store
You’re free to use whatever option you want. I’ve had some issues with the in-thread option as it sometimes caused my files not to be processed correctly (within the 60 seconds timeframe), or my thread broke for some reason (it’s beta at the time of writing, using openai==1.33.0 package).
I’ve had more luck with the out-of-thread vector store.
import glob
import datetime
now = datetime.datetime.now()
formatted_date = now.strftime("%m%d%H%M%S")
vector_store_name = f"My Context_{formatted_date}"
# Get all files in the context_folder_path
file_paths = glob.glob(f'{context_folder_path}/*')
files = []
for file_path in file_paths:
# Check if the file size is greater than 20 bytes
if os.path.getsize(file_path) > 20:
print('Adding: ', file_path)
message_file = client.files.create(
file=open(file_path, "rb"), purpose="assistants"
)
files.append(message_file)
else:
print('Ignoring: ', file_path)
file_ids = [file.id for file in files]
vector_store = client.beta.vector_stores.create(
name=vector_store_name,
file_ids=file_ids
)
I’m skipping empty files (less as 20 bytes) as they can not hold any meaningful data for my use-case.
When this script is done, the files should show up in the Azure Open AI Data Files blade.
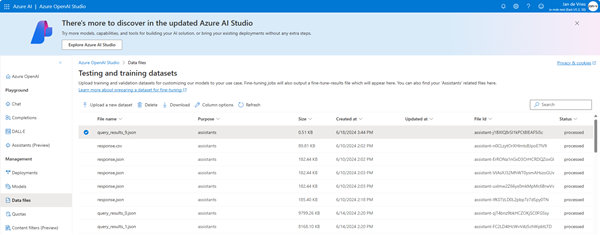
You should be able to retrieve the vector store status, but in my case it was always in the state in_progress. Even after waiting more as 50 minutes.
# This stays `in_progress`, even when all files are already with the state `processed`.
print(f'Status: {vector_store.status}')
start_time = time.time()
while vector_store.status not in ["completed", "cancelled", "expired", "failed"]:
time.sleep(5)
print("Elapsed time: {} minutes {} seconds".format(int((time.time() - start_time) // 60), int((time.time() - start_time) % 60)))
status = vector_store.status
print(f'Status: {vector_store.status}')
clear_output(wait=True)
Create an Assistant
This is fairly straightforward copy-pasting from the MS Learn pages. First, create the client for AOAI, then create an assistant.
client = AzureOpenAI(
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-05-01-preview",
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT")
)
# Create an assistant
assistant = client.beta.assistants.create(
name="Data Visualization",
instructions=f"You are a helpful AI assistant for the Sales company."
f"Data is stored in a normalized dataset. It's up to you to get clear answers based on the provided information. ",
tools=[{"type": "code_interpreter"}, {"type": "file_search"}],
model="gpt4o-sales", #You must replace this value with the deployment name for your model.
tool_resources={
"file_search": {
"vector_store_ids": [vector_store.id]
}
}
)
if debug:
print(assistant.model_dump_json(indent=2))
When creating the Assistant, a system instruction can be added, so you’re able to provide some generic instructions.
From experience, I can tell it helps if you provide valuable information over here like how the database schema is structured, aliases used for common terms, acronyms, etc.
It’s also possible to tell the assistant it can use Python (via the code_interpreter tool) and should search the provided files (via the file_search tool).
Query the data
Now for the most fun part, actually query the datasets!
I won’t pretend to be an expert in creating Python and working with notebooks, but by searching on GitHub and using GitHub Copilot, I was able to construct the following block of code to have a conversation within VS Code.
# Create a thread and attach the file to the message
thread = client.beta.threads.create()
# First, we create a EventHandler class to define
# how we want to handle the events in the response stream.
class EventHandler(AssistantEventHandler):
@override
def on_error(error):
print(error)
@override
def on_text_created(self, text) -> None:
print(f"\nassistant > ", end="", flush=True)
@override
def on_text_delta(self, delta, snapshot):
print(delta.value, end="", flush=True)
def on_tool_call_created(self, tool_call):
print(f"\nassistant > {tool_call.type}\n", flush=True)
def on_tool_call_delta(self, delta, snapshot):
if delta.type == 'code_interpreter':
if delta.code_interpreter.input:
print(delta.code_interpreter.input, end="", flush=True)
if delta.code_interpreter.outputs:
print(f"\n\noutput >", flush=True)
for output in delta.code_interpreter.outputs:
if output.type == "logs":
print(f"\n{output.logs}", flush=True)
# Then, we use the `stream` SDK helper
# with the `EventHandler` class to create the Run
# and stream the response.
while True:
followup = input("\nWhat do you want to ask? ")
if followup.lower() == "exit":
break
my_thread_message = client.beta.threads.messages.create(
thread_id = thread.id,
role = "user",
content = followup,
)
print(f"\nuser > {followup}\n", flush=True)
with client.beta.threads.runs.stream(
thread_id=thread.id,
assistant_id=assistant.id,
instructions=customInstructions,
event_handler=EventHandler(),
) as stream:
stream.until_done()
Over here I’m creating a new thread in the assistant.
Then have an event handler working with the responses, and a big while-loop prompting me to ask questions. The initial request should probably be “Get me the sales results from the last month, please.”.
When files are used, it’s also referring to these files as source material for the claims in the response. Similar to what you see in the commercial available tooling.
You can now also ask follow-up questions, as long as the data is available in the dataset. Because the code_interpreter tool is added, it will sometimes use Python to do calculations on the data, but you can also add your own functions in there, creating an even richer conversation experience. I’m not sure if the files used by the code_interpreter can also make API-calls to other endpoints, if so the possibilities would be endless!
What are my experiences with this?
I love it!
Using the Assistants is a very nice way to work with your data and get a chat experience in a short amount of time. I also asked follow-up questions like “Has the weather influenced the sales results?”. Because I have not specified any weather data it was not able to tell for sure, but still came up with an answer like: “It looks like the sales results are quite consistent in this time period. Therefore, it is likely the weather has been quite stable, not disturbing the overall sales process.”. Some might argue that it should have responded with “I can’t tell based on the data.”, which is also correct. I’m fine with both type answers.
Would I be using this for a professional solution?
At this moment my answer is: Only for proof of concept engagements.
There is a different way you can work with your own data, by using the Bring your own data to Azure Open AI and AI Search.
This approach is much more scalable and you can also tune your vectorization a bit more. Reusing data is also much easier in this scenario.
Sure, it does add complexity to the solution architecture and some costs associated with it but it’s worth it!