Adding Open AI to an existing solution with Semantic Kernel
For those of you who are reading my posts from time to time, you probably know one of my side projects is a URL minifier solution. It’s one of those services which I’ve created to learn about specific Azure services. I’m still making improvements to it and sometimes adding new features to it altogether.
With the focus on AI and large language models in just about everything nowadays, it is time for me to add it to the URL minifier too.
The feature
In essence, a URL minifier only has one job. That is to take a slug and redirect the user to the full URL which belongs to it. Simple enough.
What I like to see in this service, is a summarization feature.
This way, as a user, I don’t need to read the full site but a summary might suffice. This is also a nice ‘Hello World’-implementation to get started in the Open AI and large language models ecosystem.
What to use?
To get started you need a service that offers a large language model, like the public one offered by Open AI which you might know from ChatGPT.
There’s also the Azure Open AI service, which offers pretty much the same capabilities. Or at least that is my understanding, and I’m only starting so might be wrong on that statement. I’m using this one because it’s the service which I’ll be using during my daily work too.
A developer can interact with both of these services using HTTP requests to the appropriate endpoints. There’s even a nice Open AI client library available to make working with these services easier. I’ve used this and it certainly fits my needs.
I want to make my development a bit easier and opted to use Semantic Kernel to interact with the Open AI services. From the docs page:
Semantic Kernel (SK) is a lightweight SDK that lets you easily mix conventional programming languages with the latest in Large Language Model (LLM) AI “prompts” with templating, chaining, and planning capabilities out-of-the-box.
I’ve seen a couple of demos on how to use this SDK and from what I can tell, the implementation makes sense from a developer’s perspective. I first started out creating something similar myself, but after learning about SK I quickly dropped this work and adopted this.
Working with Semantic Kernel
With SK you don’t have to focus much on communicating with your LLM of choice. This way you can spend most of your time creating the actual prompts and tuning the configuration.
I’m learning new stuff every day, so my vision might change over time.
So far, I think is providing us developers with some hands-on (best?) practices to make our life easier. As I already mentioned, you can probably come up with something similar yourself, or adopt a similar SDK like LangChain, but using something which works out-of-the-box with my C# code is great.
When starting what you need to focus on is:
- Create an instance of
IKernel
This instance is used to communicate to the LLM and invoke Functions from Skills. - Create a Skill and Function
A skill contains one or multiple functions that can be invoked. A function consists of a prompt and configuration.
You can specify which folder(s) to load that contain the skills you want to load.
A function is a subfolder in the skills folder.
A function (the subfolder) should contain two files, config.json and skprompt.txt. Both of these files are loaded via naming conventions.
A config.json file contains most of the values you can set in any Open AI interface, like for example the temperature, penalties, and maximum tokens of the response.
The content of my URL minifier summarize function looks like this.
{
"schema": 1,
"type": "completion",
"description": "Create a summary of a specified URL.",
"completion": {
"max_tokens": 500,
"temperature": 0.3,
"top_p": 0.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0
},
"input": {
"parameters": [
{
"name": "url",
"description": "The URL which needs summarization.",
"defaultValue": ""
}
]
},
"default_backends": [ "text-davinci-003" ]
}
As you can see, I’m limiting the response to a maximum of 500 tokens and each response can differ a bit due to the temperature setting. There’s also the input parameter called url over here which will contain the full URL which I want to be summarized.
In my case, the skprompt.txt is very straightforward.
Summarize {{$url}}
If you want to do a bit more advanced stuff, you will probably fill this prompt with some samples to do few-shot learning, details of your domain, and much more stuff.
Do take into consideration, all this data in the prompt will count towards the number of tokens you send in the request. Depending on which model you are using, you might run into the maximum quite fast.
So far everything is rather straightforward. The hardest part is coming up with a useful prompt.
The Semantic Kernel GitHub repository contains some nice examples which you can use to get started. I’m using the KernelFactory from that repository, with some slight modifications, to get an instance of the IKernel configured to use my Azure Open AI service.
The only thing necessary for me is to invoke the function. An excerpt of the code looks like the following sample.
var kernel = KernelFactory.CreateForRequest(
configuration.OpenAi,
logger);
const string summaryFunctionName = "summarize";
const string skills = "minifier";
var summarizeFunction = kernel.Skills.GetFunction(skills, summaryFunctionName);
var contextVariables = new ContextVariables();
contextVariables.Set("url", url);
var result = await kernel.RunAsync(contextVariables, summarizeFunction);
if (result.ErrorOccurred)
{
throw new Exception(result.LastErrorDescription);
}
return result.Result;
You can do the same by using the Azure Open AI client library. Such an implementation looks pretty much like the following sample.
var request = $"Summarize the contents of the following web page: {url}";
OpenAIClient client = new OpenAIClient(
new Uri("https://westeurope.api.cognitive.microsoft.com/"),
new AzureKeyCredential(this.configuration.OpenAi.ApiKey));
Response<Completions> completionsResponse = await client.GetCompletionsAsync(
deploymentOrModelName: this.configuration.OpenAi.DeploymentId,
new CompletionsOptions()
{
Prompts = { request },
Temperature = (float)1,
MaxTokens = 1000,
NucleusSamplingFactor = (float)0.5,
FrequencyPenalty = (float)0,
PresencePenalty = (float)0,
GenerationSampleCount = 1,
});
Completions completions = completionsResponse.Value;
return completions.Choices[0].Text.Trim();
As you can see in the sample above, there’s a prompt in the request variable, and the settings from config.json are now set in the CompletionOptions.
If you only need to do a single request to Open AI, just use the simple client library. However, if you are planning to do more, need orchestration, remember the context, etc. do consider using Semantic Kernel. It has implemented lots of those concepts already which will make the development of solutions a lot easier.
The result
By just adding these couple of lines of code, the prompt, and configuration, the summarize feature is now implemented.
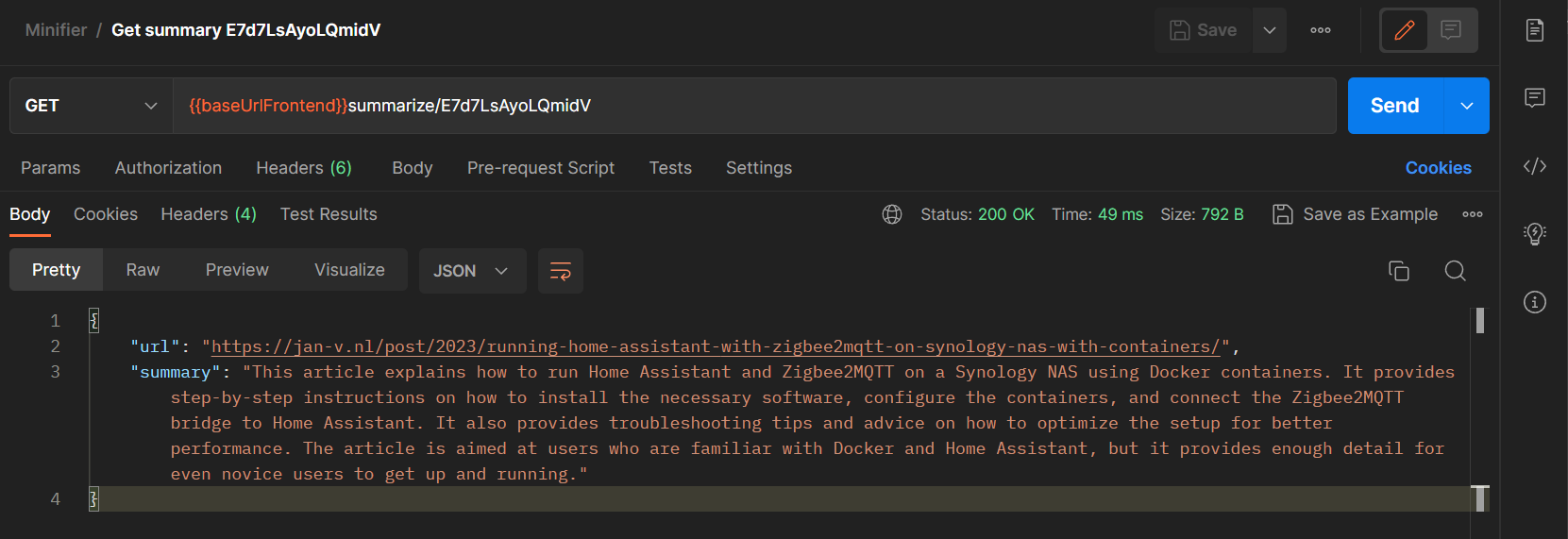
Before the current language models, it was quite hard to come up with such a feature. Nowadays, this is like writing your first ‘Hello World’-application. I’m very much looking forward to working with this technology and discovering what other amazing stuff we can create with it.